



Ten Little Algorithms, Part 4: Topological Sort
Other articles in this series:
Today we’re going to take a break from my usual focus on signal processing or numerical algorithms, and focus on a type of algorithm that, although rarely present inside embedded systems, is indispensable for developing them. In fact, you’ll get two algorithms today for the price of one.
Graph algorithms are methods of analyzing networks of nodes and edges. In the last twenty years they’ve turned into big business. Google was founded on graph theory. Facebook and LinkedIn were founded on graph theory.
And here I will take a short and wistful tangent. Sometimes it is nice for mathematics to be enjoyed for its own sake, and not because it helps earn money or fight wars. I can remember being in first or second grade: my teacher had this box of SRA cards concerning what is (or was) known as “enrichment activities” for mathematics. I always finished my math homework quickly, and to keep me busy, I guess, I got to work on the SRA cards. One of them was about the Seven Bridges of Königsberg:

In the early eighteenth century, the Prussian city of Königsberg had seven bridges over the River Pregel around the island of Kneiphof and the western tip of the neighboring island of Lomse. It was, apparently, routine for citizens of the time to enjoy meandering walks over several of the bridges; many of them attempted to take a tour of all of the bridges, without crossing any of them twice. The general opinion was that this was not possible, but no one could explain why, until the mathematician Leonhard Euler considered the problem, and presented a solution in August 1735 to colleagues at the Academy of Sciences in St. Petersburg. The Königsberg Bridge Problem was apparently well-known in the region; one of the councilmen in the nearby city of Danzig, Carl Ehler, along with a mathematics professor, Heinrich Kühn, wrote to Euler in 1736 asking if he might share his solution:
You would render to me and our friend Kühn a most valuable service, putting us greatly in your debt, most learned sir, if you would send us the solution, which you know well, to the problem of the seven Königsberg bridges together with a proof. It would prove to an outstanding example of the calculus of position [Calculi Situs] worthy of your great genius. I have added a sketch of the said bridges…
Ehler appears to have met Euler during a visit to St. Petersburg in the fall of 1734, during which he and other councilmen of Danzig negotiated for war reparations after Russia invaded the area. It is likely that Ehler was the one who brought the problem to Euler’s attention; despite Euler’s famous solution, it seems he never actually visited Königsberg.
Euler’s insight was to note that if each bridge was used only once, then each entry and exit to one of the regions required crossing two bridges. Entering (but not exiting) required crossing one bridge, and exiting (but not entering) required crossing one bridge. So a complete circuit (now known as an Eulerian path) would be possible if and only if at most two of the regions had an odd number of bridges. If all regions had an even number of bridges, such a circuit could start anywhere, and would have to finish at the starting point; if two regions had an odd number of bridges, then one would have to be the starting point and the other the ending point; if more than two regions had an odd number of bridges, a complete circuit would be impossible. In the case of Königsberg, the island of Kneiphof had 5 bridges, and each of the three areas surrounding the island (the north bank, the south bank, and the island of Lomse) had 3 bridges. Four regions, each with an odd number of bridges, and therefore it was impossible to cross each of the bridges exactly once.
The conventions of graph theory involve drawings with nodes and edges; these did not come into use until much later, but Euler’s solution to the Königsberg Bridge Problem is generally recognized as the start of graph theory.
Danzig is now part of Poland, and is named Gdansk; Königsberg is now the Russian city of Kaliningrad, and many of the bridges were destroyed in the British air raids of August 1944 or by subsequent Russian revitalization projects. But we still have graph theory.
Aside from the RSA cards, I remember reading articles from old Scientific American magazines we had on the bookshelf in our house, from the late 1970’s; one was on the recently-proved Four-Color Theorem, but mostly I just liked reading Martin Gardner’s “Mathematical Games” column on just about everything under the sun, including Ramsey numbers, even if I didn’t understand some of it. Mathematics was nice because it was interesting.

Later I learned that graph theory had applications. Not just walking-over-bridges applications, or coloring-maps-with-four-crayons applications, but useful, invaluable applications.
If you’re a computer programmer, these applications are almost certainly baked into the tools you use. Any build tool like make or ant is based on graph theory. Compilers use graph theory for register allocation. Version control systems like svn and hg and git use graph theory to manage the history of stored objects.
Martian Stew: Rattle your DAGs
How, for example, would you go about deciding the order for performing tasks with dependencies? This is a really common task; aside from the build tools I just mentioned, it shows up if you are trying to evaluate a series of expressions that are unordered:
A = B * C + 77 - D
C = 42
B = D - 1000
E = D * A
D = 99
If I’m trying to evaluate thse expressions, I have to put them in an order that makes sense. I can’t just start at the beginning and compute A = B * C + 77 - D because I don’t yet know what B and C and D are. I could just give up and complain, and force the person entering these expressions to put them in an order where nothing is undefined at time of evaluation:
C = 42
D = 99
B = D - 1000
A = B * C + 77 - D
E = D * A
But why have this requirement? I can just have the computer do it for me, by performing a topological sort.
Let’s work this out with an example. Suppose I had a couple of recipes for Martian Stew:
-
Martian Stew:
- 7 thingies
- 3 pig livers
- 6 cheese danishes
- 41 chickens
-
Cheese Danish:
- 100g flour
- 50g butter
- 2 eggs
- 1g vanilla extract
- 20g cream cheese
- 30g sugar
-
Butter:
- 100g milk
- 1g salt
-
Thingy:
- 100g iron filings
- 1 apple
- 1g vanilla extract
-
Cream cheese:
- 100g milk
- 2g salt
-
Chicken:
- 731 worms
-
Worm:
- 10g Martian Stew
-
Egg:
- 1 chicken
-
Milk:
- 1 cow
-
Cow:
- 1000kg grass
-
Pig:
- 304 apples
- 227 worms
We can view these recipes as a directed graph of ingredients:
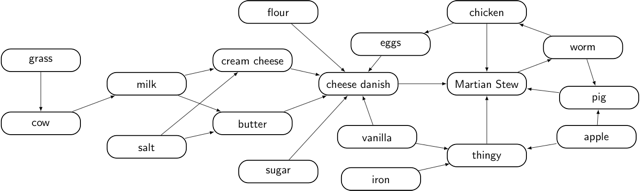
It’s a directed graph because there is a one-way relationship between ingredients and recipe output. Cow and grass do not have a symmetric relationship to each other; a cow eats grass, not the other way around.
Can you see anything wrong here? To make Martian Stew, you get three pigs, which eat the worms, which consume Martian Stew....
This graph has two cycles (Martian Stew ← pig ← worm ← Martian Stew, and Martian Stew ← chicken ← worm ← Martian Stew), and it means you can’t make Martian Stew without starting out with Martian Stew. We can fix the problem if we use worms made from apples instead of Martian Stew.
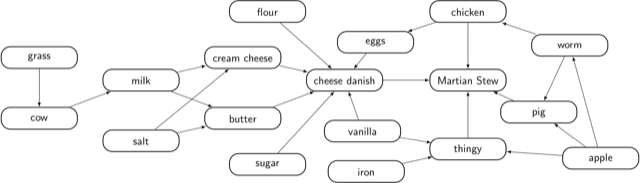
This is a directed acyclic graph, or DAG, and it can be used, among other things, to describe dependencies between tasks which can be scheduled — as opposed to tasks having cyclical dependencies, which lead to all sorts of problems.
The other type of graph is an undirected graph, which indicates symmetrical relationships between nodes. An example is a map of regions that are connected to each other, whether by bridges, as in the Königsberg case, or by borders, as in this graph of adjacent US states:
Back to our recipes for Martian Stew. Let’s say we want to go about producing each item, one by one.
If we just had the Martian Stew recipe on its own, without any subrecipes, it would be easy:
- Obtain thingies.
- Obtain pigs.
- Obtain cheese danishes.
- Obtain chickens.
- Manufacture Martian Stew from [thingies, pigs, cheese danishes, chickens].
Of course, that’s not the only possible ordering of tasks. Any of the ingredients could be obtained first:
- Obtain cheese danishes.
- Obtain chickens.
- Obtain pigs.
- Obtain thingies.
- Manufacture Martian Stew from [thingies, pigs, cheese danishes, chickens].
What makes it more complicated is all these damn subrecipes. Let’s just rewrite the list in a condensed form (remember, we had to break the cycles by using apple-fed worms, instead of raising worms the traditional way on Martian Stew):
- Martian Stew: [thingy, pig, cheese danish, chicken]
- Cheese Danish: [flour, butter, egg, vanilla, cream cheese, sugar]
- Butter: [milk, salt]
- Thingy: [iron, apple, vanilla]
- Cream cheese: [milk, salt]
- Chicken: [worm]
- Worm: [apple]
- Egg: [chicken]
- Milk: [cow]
- Cow: [grass]
- Pig: [apple, worm]
A naïve algorithm to schedule tasks from this list of recipes goes something like this, in pseudocode:
function obtainIngredient(X, list of recipes, stuff we've already obtained, output task list):
Obtain X. See if we have some already.
if we do:
Yay! We're good.
else:
No! Scan list to see if there's a recipe for it.
if there isn't:
No recipes for it. Yay! Get some, write down X at the end of the output list.
else:
Ah, there's a recipe for it.
Start manufacturing X.
for each ingredient X_k in recipe:
obtainIngredient(X_k, list of recipes, stuff we've already obtained, output task list)
Manufacture X. Yay! Write down X at the end of the output list.
and then we go through all the ingredients and run obtainIngredient() on them. If we follow this procedure, it looks something like this.
- Obtain Martian Stew. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Martian Stew.
- Obtain Thingy. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Thingy.
- Obtain Iron. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Iron at the end of the output list.
- Obtain Apple. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Apple at the end of the output list.
- Obtain Vanilla. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Vanilla at the end of the output list.
- Manufacture Thingy. Yay! Write down Thingy at the end of the output list.
- Now where were we… oh, Martian Stew.
- Obtain Pig. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Pig.
- Obtain Apple. See if we have some already. Yay, we’re good!
- Obtain Worm. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Worm.
- Obtain Apple. See if we have some already. Yay, we’re good!
- Manufacture Worm. Yay! Write down Worm at the end of the output list.
- Now where were we… oh, Pig.
- Manufacture Pig. Yay! Write down Pig at the end of the output list.
- Now where were we… oh, Martian Stew.
- Obtain Cheese Danish. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Cheese Danish.
- Obtain Flour. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Flour at the end of the output list.
- Obtain Butter. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Butter.
- Obtain Milk. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Milk.
- Obtain Cow. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Cow.
- Obtain Grass. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Grass at the end of the output list.
- Manufacture Cow. Yay! Write down Cow at the end of the output list.
- Now where were we… oh, Milk.
- Manufacture Milk. Yay! Write down Milk at the end of the output list.
- Now where were we… oh, Butter.
- Obtain Salt. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Salt at the end of the output list.
- Manufacture Butter. Yay! Write down Butter at the end of the output list.
- Now where were we… oh, Cheese Danish.
- Obtain Egg. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Egg.
- Obtain Chicken. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Chicken.
- Obtain Worm. See if we have some already. Yay, we’re good!
- Manufacture Chicken. Yay! Write down Chicken at the end of the output list.
- Now where were we… oh, Egg.
- Manufacture Egg. Yay! Write down Egg at the end of the output list.
- Now where were we… oh, Cheese Danish.
- Obtain Vanilla. See if we have some already. Yay, we’re good!
- Obtain Cream Cheese. See if we have some already. No! Scan list. Ah, there’s a recipe for it.
- Start manufacturing Cream Cheese.
- Obtain Milk. See if we have some already. Yay, we’re good!
- Obtain Salt. See if we have some already. Yay, we’re good!
- Manufacture Cream Cheese. Yay! Write down Cream Cheese at the end of the output list.
- Now where were we… oh, Cheese Danish.
- Obtain Sugar. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down Sugar at the end of the output list.
- Manufacture Cheese Danish. Yay! Write down Cheese Danish at the end of the output list.
- Now where were we… oh, Martian Stew.
- Obtain Chicken. See if we have some already. Yay, we’re good!
- Manufacture Martian Stew. Yay! Write down Martian Stew at the end of the output list.
Whew! Our output list looks like this:
- Iron
- Apple
- Vanilla
- Thingy
- Worm
- Pig
- Flour
- Grass
- Cow
- Milk
- Salt
- Butter
- Chicken
- Egg
- Cream Cheese
- Sugar
- Cheese Danish
- Martian Stew
And we did it. Did we do it efficiently? Hmmm. Well, a lot of these steps included things like “Scan list” and “See if we have some already” and those each take time. The normal computer science thing to do here is to use big-O notation and come up with some way of proving that our naive algorithm takes \( O(n^2) \) steps or whatever the number happens to be. If we double the number of items here, there’s going to be more steps, and if each step has a “Scan list” or “See if we have some already”, then we’re talking \( O(n \log n) \) or \( O(n^2) \) or something, depending on what data structure we use to keep track of the recipe lists or the set of items already obtained. Ugh.
Let’s give up on analyzing our naïve approach, and look at the conventional algorithms for topological sort. There are actually two of them: we have our choice.
Algorithm 1: Kahn’s Algorithm
This algorithm was published in 1962 and involves keeping track of which nodes aren’t dependencies of any other nodes that haven’t been added to an output list yet.
You basically maintain three data structures:
- a mapping between each node and a dependency count
- a unordered set of pending nodes
- an ordered output list of nodes
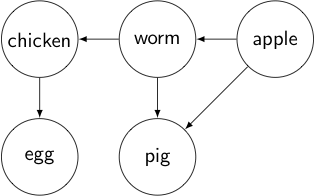
To illustrate this, I’ll show an example. Rather than use our full example, we’ll work with something simpler:
- Chicken: [worm]
- Worm: [apple]
- Apple: []
- Egg: [chicken]
- Pig: [apple, worm]
Let’s show it in graphical form:
We start by counting the number of times each item is a dependency of other items (for example, Worm and Pig both depend on Apple, so the dependency count associated with Apple is 2):
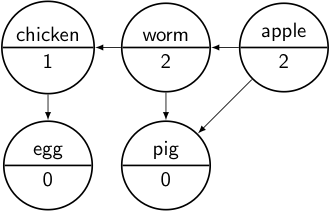
If items have a count of 0, we add them to a Pending set (shown below in yellow); these are the items that aren’t needed by the any of the items remaining:
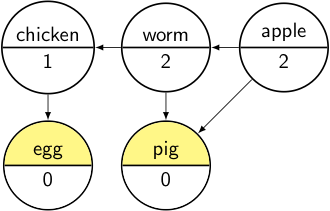
Now, we pick any item from the Pending set (e.g. egg in this case), and output that item (shown in green in the diagram below), removing it from Pending:
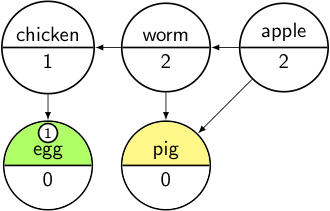
Before we are finished, we go through the item’s dependencies and subtract 1 from their dependency count; if we get to 0, we add it to the Pending list. For example, Egg’s only dependency is Chicken, so we subtract 1 from Chicken’s count, and since we get to 0, then we add it to Pending:
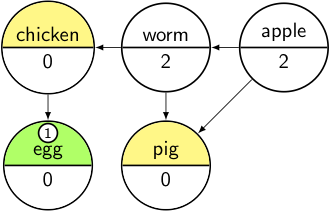
Now we repeat the process:
transfer pig from Pending to Output, decrement its dependencies' counts;
if they reach 0 add them to Pending
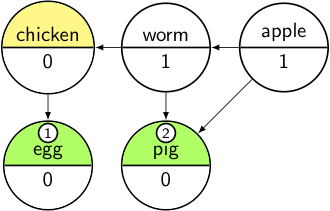
And again:
transfer chicken from Pending to Output, decrement its dependencies' counts;
if they reach 0 add them to Pending
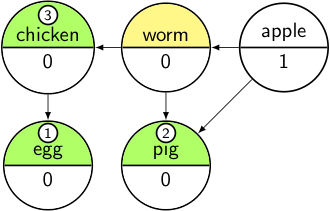
And again:
transfer worm from Pending to Output, decrement its dependencies' counts;
if they reach 0 add them to Pending
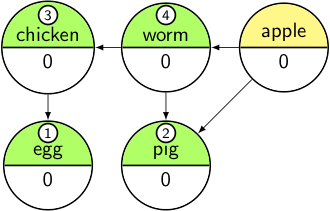
And finally:
transfer apple from Pending to Output, decrement its dependencies' counts;
if they reach 0 add them to Pending
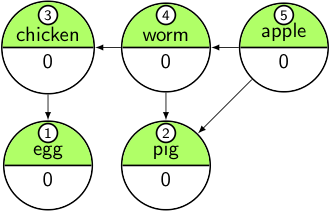
The resulting output list (egg, pig, chicken, worm, apple) shows the dependencies in “reverse” order, namely each item precedes all of its dependencies. If we want to get a list of items in order so that each item is preceded by all of its dependencies, we have to reverse the list:
[apple, worm, chicken, pig, egg]
We have one more thing to do at the end: we need to check all our nodes and make sure they all have a dependency count of 0. If some of them don’t, then those nodes are interconnected with a cycle, and the algorithm fails.
The unordered Pending set can use a queue or a stack or a hash set as an underlying data structure; the intent is to have O(1) insertion and removal costs. I’d probably use a stack since it’s the simplest.
If you study this algorithm, it’s not hard to show that the time it takes is \( aN+bE \), a weighted sum of the number of nodes and the number of edges. It’s a faster algorithm than our naïve algorithm because there’s no searching involved, at least if we store each count in an augmented structure along with the associated node. The initial scan to setup the counts requires N+E steps; the transfering to Pending and then to Output we perform once for each node, so it takes N steps; the decrementing of counts we perform once for each edge, so it takes E steps; and the reversal takes N steps (for example, pushing all items onto a stack and popping them off).
Algorithm 2: Depth-first Search
The other algorithm uses a depth-first search traversal. Depth-first search is a way of searching all nodes in a graph or a tree. (A tree is really just a special case of a directed acyclic graph, with only one root and only one path from the root to each of the other nodes.) It’s sort of like a guy cleaning a room who gets easily distracted:
Guy cleans shelf, containing a box and a looseleaf binder.
Guy looks at the binder and says “Ooh! a binder!” and forgets about everything else for a moment. In the binder are a bunch of old bills and a newspaper clipping about Monica Lewinsky. One of the bills is a telephone bill from 1997. He keeps the newspaper clipping and the telephone bill and puts the other bills through a paper shredder.
Guy looks at the telephone bill and says “Ooh! A telephone bill!” and looks to see if he remembers any of the phone numbers or associated cities.
Guy looks at the binder trying to remember what he was doing before, then looks at the box and says “Ooh! A box!” and forgets about everything else and goes through the items in the box, which are an old 3½-inch floppy disk, a Koosh ball, and a button saying DUKAKIS/BENTSEN ‘88. He tosses the button in the garbage.
Guy looks at the floppy disk and say “Ooh! A floppy disk!” and goes to find a floppy disk drive so he can see what’s on it. He connects it to his computer and puts the floppy disk in and types DIR and sees a bunch of files which he remembers as raunchy jokes from several Usenet newsgroups....
This anecdote illustrates a depth-first search of a tree:
- shelf
- binder
- bills
- telephone bill
- …
- newspaper clipping
- bills
- box
- campaign button
- Koosh ball
- floppy disk
- collection of raunchy jokes
- binder
With a tree, we just search each node and all of its descendents before going onto sibling nodes. With a graph, we have to keep track of where we’ve been before (especially if it’s a cyclic graph, otherwise we get caught in an infinite loop) so that we don’t repeat searches.
The topological sort utilizing a depth-first search is essentially the same as our naïve algorithm, but with some minor changes. Let’s look again at the naïve algorithm we showed earlier:
function obtainIngredient(X, list of recipes, stuff we've already obtained, output task list):
Obtain X. See if we have some already.
if we do:
Yay! We're good.
else:
No! Scan list to see if there's a recipe for it.
if there isn't:
No recipes for it. Yay! Get some, write down X at the end of the output list.
else:
Ah, there's a recipe for it.
Start manufacturing X.
for each ingredient X_k in recipe:
obtainIngredient(X_k, list of recipes, stuff we've already obtained, output task list)
Manufacture X. Yay! Write down X at the end of the output list.
And let’s fix it to be efficient. To avoid the scanning and checking steps, we’re going to do it this way (and while we’re at it, let’s generalize to any kind of topological sort, not just recipes):
function toposort_helper(node, output task list):
if node is marked as unvisited:
mark node as visited
for each subnode in node's edges:
toposort_helper(subnode, output task list)
add node to output task list
function toposort_dfs(graph):
for each node in graph:
mark node as unvisited
output task list = empty list
for each node in graph:
toposort_helper(node, output task list)
return output task list
Here the only explicit data structures we need are a boolean field associated with each node stating whether we’ve visited that node already, along with the output list. This is a recursive algorithm, so we need the computer’s stack as an implicit data structure that our language implementation manages. It’s possible to rewrite this algorithm using an iterative implementation, but then we need to maintain a stack so we can remember what we were doing in the previous node.
Let’s run through it for the simple example pointed out earlier:
output: []
stack:
- for each node in [chicken, worm, apple, egg, pig]
node = chicken → it’s unvisited, so we mark it as visited and iterate through its dependencies.
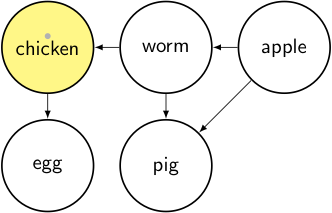
output: []
stack:
- toposort_helper(chicken): for each node in [worm]
- for each node in [chicken, worm, apple, egg, pig]
node = worm → it’s unvisited, so we mark it as visited and iterate through its dependencies.
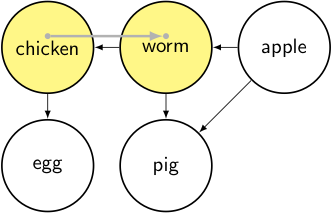
output: []
stack:
- toposort_helper(worm): for each node in [apple]
- toposort_helper(chicken): for each node in [worm]
- for each node in [chicken, worm, apple, egg, pig]
node = apple → it’s unvisited, so we mark it as visited and iterate through its dependencies.
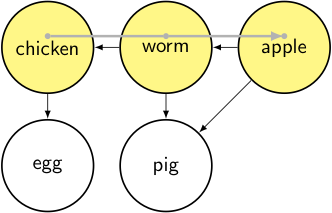
output: []
stack:
- toposort_helper(apple): for each node in []
- toposort_helper(worm): for each node in [apple]
- toposort_helper(chicken): for each node in [worm]
- for each node in [chicken, worm, apple, egg, pig]
The node = apple has no outgoing edges, so we’re done: add it to the output and pop back up to the previous node.
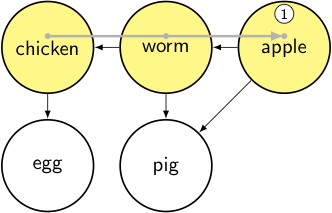
output: [apple]
stack:
- toposort_helper(worm): for each node in [apple]
- toposort_helper(chicken): for each node in [worm]
- for each node in [chicken, worm, apple, egg, pig]
We’ve now finished all of worm’s edges, so we’re done: add it to the output and pop back up to the previous node.
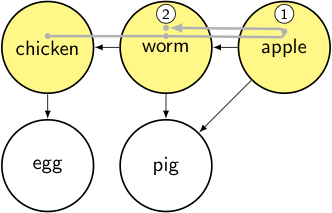
output: [apple, worm]
stack:
- toposort_helper(chicken): for each node in [worm]
- for each node in [chicken, worm, apple, egg, pig]
We’ve now finished all of chicken’s edges, so we’re done: add it to the output and pop back up to the previous node.
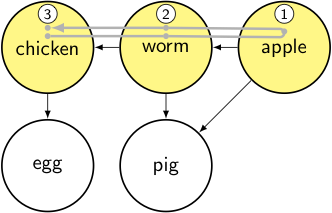
output: [apple, worm, chicken]
stack:
- for each node in [chicken, worm, apple, egg, pig]
node = worm → it’s already been visited, so we move on.
output: [apple, worm, chicken]
stack:
- for each node in [chicken, worm, apple, egg, pig]
node = apple → it’s already been visited, so we move on.
output: [apple, worm, chicken]
stack:
- for each node in [chicken, worm, apple, egg, pig]
node = egg → it’s unvisited, so we mark it as visited and iterate through its dependencies.
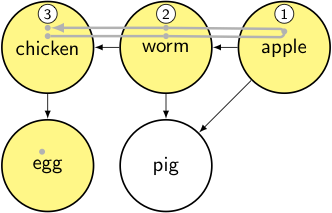
output: [apple, worm, chicken]
stack:
- toposort_helper(egg): for each node in [chicken]
- for each node in [chicken, worm, apple, egg, pig]
node = chicken → it’s already been visited, so we pop back up.
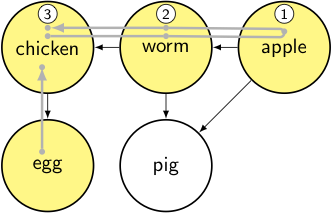
node = egg, which is done, so we add it to the output list and pop back up.
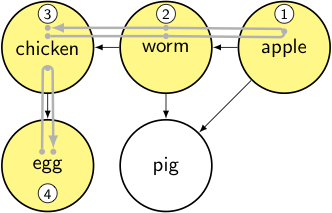
output: [apple, worm, chicken, egg]
stack:
- for each node in [chicken, worm, apple, egg, pig]
node = pig → it’s unvisited, so we mark it as visited and iterate through its dependencies.
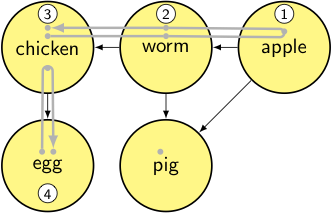
output: [apple, worm, chicken, egg]
stack:
- toposort_helper(pig): for each node in [worm, apple]
- for each node in [chicken, worm, apple, egg, pig]
node = worm → it’s already been visited, so we pop back up.
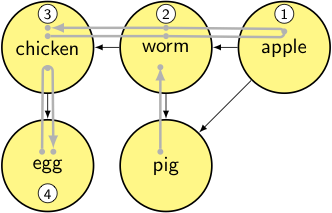
stack:
- toposort_helper(pig): for each node in [worm, apple]
- for each node in [chicken, worm, apple, egg, pig]
node = apple → it’s already been visited, so we pop back up.
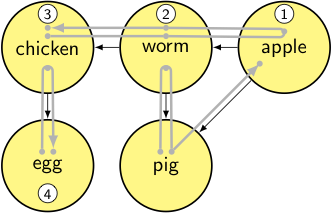
Now we’re done with the pig node, so we add it to the output list and pop back up… and we’re done.
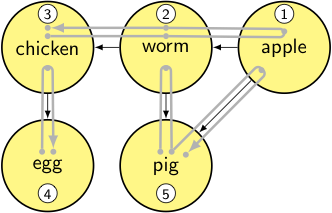
output: [apple, worm, chicken, egg, pig]
This time the output is in the order we want (apple, worm, chicken, egg, pig): an item does not appear until each of the dependencies are already added first.
Here the running time is a weighted sum \( aN+bE \) of the number of nodes and edges also, because unlike our earlier naïve algorithm, we don’t have to do any extra scanning to determine whether a node has already been included in our output list; that’s already captured by the visited flag. You’ll note in the last figure shown above that for each edge, we show it as traversed twice, once representing a new call for the toposort_helper() function for the adjacent node in each edge, then as a pop back up when the call returns.
Which is better?
So which of these algorithms is better? Well, they both have more or less the same behavior of execution time, \( aN+bE \). I like Kahn’s algorithm better, for a couple of reasons:
- it doesn’t require recursion
- the data structures used are fairly simple
- if there are cycles, it can identify all of the nodes containing cycles
The depth-first-search algorithm will get stuck the first time it encounters a cycle (in fact, our implementation ignores cycles and keeps on going; the variant shown in the Wikipedia article uses two types of marks for visited nodes, one “temporary” and one “permanent”, to be able to detect a cycle). If you know ahead of time that the graph is acyclic, and you don’t have any dislike of recursion, then the depth-first-search algorithm is a bit simpler to implement.
Representing graphs
Representing nodes in a graph is an easy task: just store them in an array, perhaps with a hash map to lookup the node by name. There are two main methods of representing a graph’s edges:
One is called the adjacency list representation. For each node, we keep a list of references to the adjoining nodes, one for each adjoining edge. We’ve used this representation in our examples.
The other approach is an N × N matrix of boolean values. For our minimalist chicken/worm/apple/egg/pig example, it looks like this:
| C | W | A | E | P | |
|---|---|---|---|---|---|
| C | 0 | 1 | 0 | 0 | 0 |
| W | 0 | 0 | 1 | 0 | 0 |
| A | 0 | 0 | 0 | 0 | 0 |
| E | 1 | 0 | 0 | 0 | 0 |
| P | 0 | 1 | 1 | 0 | 0 |
A 1 represents a dependency and a 0 represents a lack of dependency. For example, row C (chicken) and column W (worm) contains a 1, showing that a chicken depends on a worm.
The matrix representation is better in some ways for theoretical analysis, and it’s great if you want to know if there is an edge or not between a particular pair of nodes; this is \( O(1) \) lookup time — the adjacency list has worst-case lookup time of \( O(N) \). But if you want to look at the outgoing edges of each node, you always have to look at N entries in the graph. This means to scan all of the graph’s edges requires a runtime of \( O(N^2) \). For topological sort, this is a downside, so an adjacency list is better.
On the other hand, if you have an adjacency list of incoming edges, and you want to find the list of outgoing edges of a particular node (or vice-versa: you have an adjacency list of outgoing edges, and you want to find the list of incoming edges of a particular node), this requires a scan of all edges (E steps), whereas the matrix representation only requires a scan of all nodes (N steps). For nodes with lots of connections this can take much longer.
In short: which representation is better depends on your purpose for using the graph.
Python code for topological sort
Below are Python implementations for both of these algorithms (Kahn’s and the depth-first-search), along with the full Martian Stew example. First we need to construct a representation of a graph from input data.
recipes = [
['martian stew', 'thingy,pig,cheese danish,chicken'],
['cheese danish', 'flour,butter,egg,vanilla,cream cheese,sugar'],
['butter', 'milk,salt'],
['thingy', 'iron,apple,vanilla'],
['cream cheese', 'milk,salt'],
['chicken', 'worm'],
['worm', 'apple'],
['egg', 'chicken'],
['milk', 'cow'],
['cow', 'grass'],
['pig', 'apple,worm']
]
def to_graph(recipes):
''' get recipes into a canonical form for further manipulation '''
nodes = []
nodemap = {}
def add_node(name):
if name in nodemap:
node = nodemap[name]
else:
node = {'name': name}
nodes.append(node)
nodemap[name] = node
return node
for recipe, ingredients in recipes:
ingredients = ingredients.split(',')
node = add_node(recipe)
node['edges'] = tuple(ingredients)
for ingredient in ingredients:
node = add_node(ingredient)
for node in nodes:
if 'edges' in node:
node['edges'] = tuple(nodemap[ingredient] for ingredient in node['edges'])
else:
node['edges'] = ()
return nodes
# Print a list of the nodes along with the outgoing edges of each:
for n in to_graph(recipes):
print "%-20s" % n['name'], [n2['name'] for n2 in n['edges']]
martian stew ['thingy', 'pig', 'cheese danish', 'chicken'] thingy ['iron', 'apple', 'vanilla'] pig ['apple', 'worm'] cheese danish ['flour', 'butter', 'egg', 'vanilla', 'cream cheese', 'sugar'] chicken ['worm'] flour [] butter ['milk', 'salt'] egg ['chicken'] vanilla [] cream cheese ['milk', 'salt'] sugar [] milk ['cow'] salt [] iron [] apple [] worm ['apple'] cow ['grass'] grass []
The 57-step example of the naïve algorithm was generated using the depth-first search implementation — run with verbose=True to see this; if you don’t need the verbose description just delete the associated lines that utilize printer from the function.
def step_printer():
k = [0]
def step(text):
k[0] += 1
print "%d. %s" % (k[0], text)
return step
def toposort_depthfirst(recipes, verbose=False):
nodes = to_graph(recipes)
printer = step_printer() if verbose else (lambda text: None)
output = []
for node in nodes:
node['visited'] = False
def visit(node, context=None):
title = node['name'].title()
if not node['visited']:
node['visited'] = True
if not node['edges']:
printer("Obtain %s. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *%s* at the end of the output list." % (title,title))
else:
printer("Obtain %s. See if we have some already. No! Scan list. Ah, there's a recipe for it." % title)
printer("Start manufacturing %s." % title)
for n in node['edges']:
visit(n, context=node)
printer("Manufacture %s. Yay! Write down *%s* at the end of the output list." % (title,title))
if context:
printer("Now where were we... oh, %s." % (context['name'].title()))
output.append(node)
else:
if context:
printer("Obtain %s. See if we have some already. Yay, we're good!" % title)
for node in nodes:
visit(node)
return output
output = toposort_depthfirst(recipes, True)
print ''
print '\n'.join(node['name'].title() for node in output)1. Obtain Martian Stew. See if we have some already. No! Scan list. Ah, there's a recipe for it. 2. Start manufacturing Martian Stew. 3. Obtain Thingy. See if we have some already. No! Scan list. Ah, there's a recipe for it. 4. Start manufacturing Thingy. 5. Obtain Iron. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Iron* at the end of the output list. 6. Obtain Apple. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Apple* at the end of the output list. 7. Obtain Vanilla. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Vanilla* at the end of the output list. 8. Manufacture Thingy. Yay! Write down *Thingy* at the end of the output list. 9. Now where were we... oh, Martian Stew. 10. Obtain Pig. See if we have some already. No! Scan list. Ah, there's a recipe for it. 11. Start manufacturing Pig. 12. Obtain Apple. See if we have some already. Yay, we're good! 13. Obtain Worm. See if we have some already. No! Scan list. Ah, there's a recipe for it. 14. Start manufacturing Worm. 15. Obtain Apple. See if we have some already. Yay, we're good! 16. Manufacture Worm. Yay! Write down *Worm* at the end of the output list. 17. Now where were we... oh, Pig. 18. Manufacture Pig. Yay! Write down *Pig* at the end of the output list. 19. Now where were we... oh, Martian Stew. 20. Obtain Cheese Danish. See if we have some already. No! Scan list. Ah, there's a recipe for it. 21. Start manufacturing Cheese Danish. 22. Obtain Flour. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Flour* at the end of the output list. 23. Obtain Butter. See if we have some already. No! Scan list. Ah, there's a recipe for it. 24. Start manufacturing Butter. 25. Obtain Milk. See if we have some already. No! Scan list. Ah, there's a recipe for it. 26. Start manufacturing Milk. 27. Obtain Cow. See if we have some already. No! Scan list. Ah, there's a recipe for it. 28. Start manufacturing Cow. 29. Obtain Grass. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Grass* at the end of the output list. 30. Manufacture Cow. Yay! Write down *Cow* at the end of the output list. 31. Now where were we... oh, Milk. 32. Manufacture Milk. Yay! Write down *Milk* at the end of the output list. 33. Now where were we... oh, Butter. 34. Obtain Salt. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Salt* at the end of the output list. 35. Manufacture Butter. Yay! Write down *Butter* at the end of the output list. 36. Now where were we... oh, Cheese Danish. 37. Obtain Egg. See if we have some already. No! Scan list. Ah, there's a recipe for it. 38. Start manufacturing Egg. 39. Obtain Chicken. See if we have some already. No! Scan list. Ah, there's a recipe for it. 40. Start manufacturing Chicken. 41. Obtain Worm. See if we have some already. Yay, we're good! 42. Manufacture Chicken. Yay! Write down *Chicken* at the end of the output list. 43. Now where were we... oh, Egg. 44. Manufacture Egg. Yay! Write down *Egg* at the end of the output list. 45. Now where were we... oh, Cheese Danish. 46. Obtain Vanilla. See if we have some already. Yay, we're good! 47. Obtain Cream Cheese. See if we have some already. No! Scan list. Ah, there's a recipe for it. 48. Start manufacturing Cream Cheese. 49. Obtain Milk. See if we have some already. Yay, we're good! 50. Obtain Salt. See if we have some already. Yay, we're good! 51. Manufacture Cream Cheese. Yay! Write down *Cream Cheese* at the end of the output list. 52. Now where were we... oh, Cheese Danish. 53. Obtain Sugar. See if we have some already. No! Scan list. No recipes for it. Yay! Get some, write down *Sugar* at the end of the output list. 54. Manufacture Cheese Danish. Yay! Write down *Cheese Danish* at the end of the output list. 55. Now where were we... oh, Martian Stew. 56. Obtain Chicken. See if we have some already. Yay, we're good! 57. Manufacture Martian Stew. Yay! Write down *Martian Stew* at the end of the output list. Iron Apple Vanilla Thingy Worm Pig Flour Grass Cow Milk Salt Butter Chicken Egg Cream Cheese Sugar Cheese Danish Martian Stew
And here’s Kahn’s algorithm:
def toposort_kahn(recipes, verbose=False):
nodes = to_graph(recipes)
# Each node N gets a count of the number of other nodes with dependencies on N.
for node in nodes:
node['count'] = 0
for node in nodes:
for n in node['edges']:
n['count'] += 1
if verbose:
for node in nodes:
print node['name'], node['count']
output = []
pending = [node for node in nodes if node['count'] == 0]
while pending:
node = pending.pop()
output.append(node)
for n in node['edges']:
n['count'] -= 1
if n['count'] == 0:
pending.append(n)
remaining_nodes = [node['name'] for node in nodes if node['count'] > 0]
if remaining_nodes:
raise ValueError('Graph has cycles in these nodes: '+str(remaining_nodes))
return list(reversed(output))
for node in toposort_kahn(recipes):
print node['name'].title()Iron Apple Vanilla Thingy Worm Pig Flour Grass Cow Milk Salt Butter Chicken Egg Cream Cheese Sugar Cheese Danish Martian Stew
And remember, Kahn’s algorithm does a great job of detecting which nodes have cycles:
recipes2 = [
['martian stew', 'thingy,pig,cheese danish,chicken'],
['cheese danish', 'flour,butter,egg,vanilla,cream cheese,sugar'],
['butter', 'milk,salt'],
['thingy', 'iron,apple,vanilla'],
['cream cheese', 'milk,salt'],
['chicken', 'worm'],
['worm', 'egg'],
['egg', 'chicken'],
['milk', 'cow'],
['cow', 'grass'],
['pig', 'apple,worm']
]
sorted_nodes = toposort_kahn(recipes2)Wrapup
Today we looked briefly at the concept of graphs and topological sorting. A graph is a set of nodes connected by edges in some manner. If the edges represent an asymmetrical relationship, the graph is a directed graph, and it can either be cyclic or acyclic depending on the particular arrangement of edges. If the edges represent a symmetrical relationship, the graph is an undirected graph.
Topological sort is a way of sorting the nodes of a directed acyclic graph (DAG) into an ordered list, so that each node is preceded by the adjacent nodes of its outgoing edges (or incoming edges, if you want to reverse the order). It is used in determining the order to evaluate expressions or execute tasks when there are dependencies.
There are two simple algorithms for a topological sort, Kahn’s algorithm and a depth-first-search algorithm. Both have execution times that are proportional to a weighted sum of the number of nodes and edges \( aN + bE \).
I have given implementations here in Python for both algorithms.
I hope you have found this material useful and enjoyed the article!
© 2015 Jason M. Sachs, all rights reserved.




- Comments
- Write a Comment Select to add a comment
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:



