



Finite State Machines (FSM) in Embedded Systems (Part 4) - Let 'em talk
Welcome to the fourth part of my two-part article on state machines (1). This post topic has been suggested by Miro Samek, who, in a comment to my first post, wrote: "The biggest issues are not so much with the state machine implementations [...]. Instead, the biggest issues are with the code surrounding state machines.".
Indeed Miro is right, many
problems come from outside state machines, how they are integrated into the system, and how they interact. I left this as
last since I reckon these problems affect every
processing device. Be it a state machine, a stateless function, a concurrent thread, or a stack-based parser,
when this entity needs to access (or be accessed from) the
environment there are some questions you need to answer to ensure the system's correctness. Is the information
you are looking for ready? Is it still valid? Is there a chance that
it is changing when you access it? For the sake of simplicity, throughout this post, I'll use the term
machine to refer to any kind of processing entity in a concurrent system.
Moreover, according to the software's application domain, you may need to provide results in a timely constraint or relinquish processor cycles as soon as possible.
This post aims to give you a general overview of what to expect when designing and implementing a concurrent system without going into specific details of each case. Also, the code snippets provided are intended to illustrate concepts and inspire ideas, rather than being directly used in your project.
Quick Links
- Part 1: Finite State Machines (FSM) in Embedded Systems (Part 1) - There's a State in This Machine!
- Part 2: Finite State Machines (FSM) in Embedded Systems (Part 2) - Simple C++ State Machine Engine
- Part 3: Finite State Machines (FSM) in Embedded Systems (Part 3) - Unuglify C++ FSM with DSL
- Part 4: Finite State Machines (FSM) in Embedded Systems (Part 4) - Let 'em talk
How to feed a machine
In a previous post, I wrote about my first significant experience with state machines (in Z80 assembly for GameBoy Color). In that project, I had several FSM-powered game objects (in the order of 20-40) that interacted directly with the game engine.
Good computer science theory and good FSM practice would have required me to design a message-based communication framework to queue events and feed them to the FSM, but working in assembly was not very comfortable, computing resources were scarce, and we got continuous requests for change and new behaviors from the game design team (and it was before agile became a thing).
For these reasons, I opted for a simplified design - the game scheduler super-loop gave each active Game Object a slice of time every iteration of the loop, to perform their activities in a cooperative round-robin fashion. The FSM spent its time slice executing the current state function, checking for conditions that would trigger a reaction and/or a transition.
This is what I (recently) learned to be
an
input-driven state machine. You
may think of it as a polling mechanism – the specific function
code repeatedly polls the inputs. There is no way for the machine to sleep until something happens.
This design is trivial to implement and lets you get over the burden of defining events and setting up a dedicated infrastructure of event queuing and delivering, but the advantages stop here.
In this listing, you can see an example of how an input machine system can be implemented.
#include <vector>
#include <memory>
class Machine {
public:
virtual void doYourJob() = 0;
private:
};
[[noreturn]]
void scheduler( std::vector<std::unique_ptr<Machine>> const& machines )
{
while( true ) {
for( auto const &m: machines ) {
m->doYourJob();
}
// synchronize/wait
}
}
This approach doesn't scale well. All objects are always invoked even if they are idly waiting for some time to elapse. The conditions are repeatedly polled even if they are unlikely to change. Also, the same condition may be checked by several entities in the same round.
The external scheduler becomes quite important since it is up to this component to decide when and how often to call the machine. If you exceedingly simplify the scheduler by using an unsynchronized simple loop then your machine will be called at the maximum frequency achievable from the CPU, maybe leaving other parts of the system starving or leading to unnecessary high power consumption.
Dependencies are also problematic in this design. If your machine needs inputs from several parts of the system you’ll end up with a god object that explicitly depends on almost everything, making it harder to refactor and reuse the component.
Testing is
equally hard. To test your machine, you need to mock up all the parts of the environment that are polled by the FSM. If the machine has many dependencies, this leads you to a great deal of mocking.
Finally, this is not very friendly with concurrency. If you are polling a shared value, that may mutate anytime in a non-atomic way, then you need to set up some arbitration mechanism, such as a mutex, or double buffering, to avoid critical runs.
On the other side of the ring, enters the event-driven state machine. This machine idly waits for events and reacts only when an event is received. It gets no time slice, so when the FSM is not reacting to an event, it consumes no CPU at all.
These FSMs are light in execution and light in power consumption. Concurrency is easy to get right, as long as you process one event at a time in the same machine.
And
finally, events provide a uniform way to get information into the machine. On one side this makes the code more readable,
lowering the cognitive load, on the other side it simplifies testing. With an event-driven machine, there is no need for input mock-ups - you simply create events and feed them to the machine.
On the downside, you need to design a message-passing system. The event data structure must be defined in such a way as to accommodate all the possible produced events. All event producers must have a way to address intended recipients. If events are not consumed right after their production, you also need a queue. The queue may be individual for each machine, or global if shared among all machines.
A single queue event-driven machine system skeleton may look like the following code:
#include <memory>
#include <deque>
#include <vector>
struct Event {};
class Machine {
public:
virtual void dispatch( Event const& event ) = 0;
private:
};
class Dispatcher {
public:
void send( std::unique_ptr<Event>&& e ) {
// prevent dispatch to be called now.
queue.push_front( std::move(e) );
}
void dispatch() {
// prevent changes in queue and consumers
while( !queue.empty() ) {
auto const& e = *queue.back();
for( auto const& m : machines ) {
m->dispatch(e);
}
queue.pop_back();
}
}
private:
std::deque<std::unique_ptr<Event>> queue;
std::vector<std::unique_ptr<Machine>> machines;
};
In this code, you may notice that there is no way for a machine to define its interest in events of one kind or another. For this reason, all the events are sent to all the machines, if they are not interested they'll dump the event. This may be made more efficient, but it would require much more complicated code and may be beyond the scope of small projects.
A queue for each machine solves the interest problem since it is the event sender that knows which recipients are interested in the message but requires more memory, and a way to share the address of the recipients to the senders.
struct Event {};
class Machine {
public:
void send( std::unique_ptr<Event>&& event ) {
// prevent concurrent access to queue
queue.push_front( std::move(event) );
}
void process() {
while( !queue.empty() ) {
// prevent concurrent access to queue
auto const& e = *queue.back();
dispatch(e);
queue.pop_back();
}
}
virtual void dispatch( Event const& event ) = 0;
private:
std::deque<std::unique_ptr<Event>> queue;
};
[[noreturn]]
void scheduler( std::vector<std::unique_ptr<Machine>> const& machines )
{
while( true ) {
for( auto const &m: machines ) {
m->process();
}
// synchronize/wait
}
}
This is quite similar to the input-driven machine since the scheduler's only job is giving time slices to each machine. It is up to the machine to use the time for processing the event queue. What is not shown in the listing is the infrastructure needed for a sender to deliver a message to the intended recipient.
Software is flexible, so you can transform an input-driven machine into an event-driven machine and vice-versa. From the machine point of view, the transformation is not dramatic:
- input to event - on the time-slice the machine polls for events in the inbound bin;
- event to input - a time-slice event is sent to the machine each turn so that input polling can be performed.
What is harder is to change the environment from a passive approach where you need to poll conditions, to an active one where conditions trigger events sent to the dispatcher.
To Block or not to block
Regardless of the model you chose, your machine may need to wait for a time-consuming operation to complete. Be it another thread to complete a computation, an I/O operation, or a mutex to become free, if we block the thread waiting for the event to happen, we are causing problems to the application.
The reason is intuitive on a bare metal MCU with a single thread but blocking is a problem also on a multi-core server CPU.
Two points are worth noticing to convince yourself (I had to convince myself) that blocking is to avoid also on current generation PCs -
- When you block your thread, a context switch occurs, so that the CPU can be assigned to something else in the ready bin. Context switching is expensive and doing it too often causes the application (and the computer) to perform badly.
- When the CPU executes your FSM code, if there is no blocking call, the thread executes machines one after the other until no more events are pending. Blocking a thread will also block all the other FSMs powered by this thread.
For these reasons, you should always avoid blocking calls (IO read or writes, mutex locks, flag polling, sleep, wait for std::future, or any other kind of event). If possible they have to be replaced with asynchronous versions, otherwise, they may be executed by another thread (possibly from a thread pool) and get notified by the thread on completion.
How to get information out
This problem is similar to feeding the machine. The first solution that comes to mind is simple, intuitive, and most of the time: using a getter. OOP, as implemented by Java and C++, taught us to access object properties via getters, i.e. object functions that decouple the internal state of the object from object users, but this method falls short in a concurrent system.
This may be fine if we need a piece of immutable information from the machine (e.g. querying the packet receive timeout), but becomes problematic if we need information that may change over time. Suppose that the machine combines some asynchronous information to produce a value that expires after some time. The getter function call runs in the caller thread, while the machine runs in the machine thread. This means that the value I want to read may be non-valid yet, valid, or being written and there is no way to know for sure.
Adding a synchronization here means
that we are going to block either the querying thread, the machine
thread, or both at different times. And yet, we may get something that is outdated.
A better solution is to ask the machine for a value. This can be done by setting up a request/response message pattern. Since we don't want to block the requesting thread, the requester should have an event-based implementation.
It is not as trivial as the getter function – you need to let the information provider know who is asking so that the reply can travel the right way to the requester.
An alternative way is to use a callback. The requester provides the provider a callback function so that the provider will call the callback each time the information changes (or periodically). The callback may be provided either at construction time or via a dedicated event. What you need to keep in mind is that the callback is executed in the machine thread, meaning that the time spent in the callback is time stolen to event reactions. Therefore these callbacks must not be blocked.
Note that even when using callbacks, if the information is required by a machine, the easiest and safest way to route the information from the callback to the requesting machine is by sending a message to itself. As shown in the following C++ pseudo-code:
#include <functional>
class Server
{
public:
using Value = int; // whatever the type of the provided value is.
void registerValueCallback( std::function<void(Value)> callback );
};
FsmServer gServer;
class NewValue : public Event
{
public:
NewValue( Server::Value value );
};
class Requester
{
public:
Requester()
{
gServer.registerValueCallback( [this]( Server::Value newValue ) {
send( this, std::make_unique<NewValue>( newValue ));
});
}
};
Event queue hiccups
Several things can go wrong with the event queue (and C++). Your machine is getting the CPU when the dispatcher is processing the event queue, so if the machine wants to send an event, there is a potential concurrent access to the event queue. Trying to do this in C++ without proper precautions, will result in iterator invalidation and potential undefined behavior.
So you have opted for an event machine and you also decided that your timers deliver events. Possibly you have an event queue to decouple event generation from event processing. What can go wrong?
Picture this state machine:
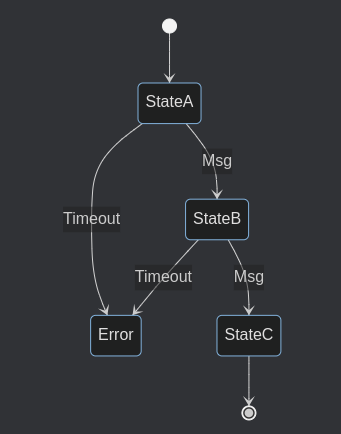
Upon entering StateA you set up a timeout timer because you will wait for an input (Msg) that may or may not arrive. Upon receiving the input you will cancel the timer and transition to StateB.
Consider now, that the timer is almost over when a Msg event enters the queue. Right after Msg is in the queue, but before the state machine has a chance to process its queue, the timer fires the timeout event. Now you have two events in the queue – the input and the timeout.
Your state machine processes the first event. Good! It is the information we longed for, let’s call the timer cancel function, and transition to the StateB.
On entering StateB we set the timeout timer again because we are waiting for another Msg to arrive. Then we continue with the event processing.
The next message in the queue is the timeout, which is popped out and served to the machine. Ouch, this is the same type of timeout event we are waiting for!
When using queues you may receive events that you don't expect because you explicitly asked not to receive them.
It is easy to fall for this kind of aliasing (actually this bug happened to me... more than once). There are some solutions you can apply:
- differentiate events (either a different event, or a different timer identifier)
- do not queue timer events (or queue them in a high-priority queue)
- let the timer cancel operation remove timeout events from the queue (this can be done physically, or logically by discarding the canceled timer event when it’s popped out of the queue).
Regardless of the solution be aware of the problem if you don't want to be bitten in the back.
Conclusions
In this article, I scraped the surface of the problems you can find in a system where different parts need to communicate together and presented some design options that can help.
Likely, every project has, at least some, these specificities – be it an interrupt, the need to perform two operations independently at the same time, or the requirement for low power.
Going from input-driven to event-driven machines is the first key step to enable many improvements and allow for more efficient use of the system resources.
Overall machines are better modeled as closed systems, with no user access methods. The concurrency problems are mostly avoided when restricting communication to messages both for setting and querying values.
Dealing with event queues may yield some surprises, such as timeout events popping out after their expiration.
This marks the last part of this series, I hope you enjoyed the journey.
1. When planning what to write I was overly optimistic about the content, only after I started writing I realized that I needed to split this into several parts. [back]




- Comments
- Write a Comment Select to add a comment
Noticed that you have tried to uses UML for the state diagram, a better program to do this is Draw.io, it has good support for all UML including state diagrams and is free.

Thank you for your suggestion, Andrew. For the chart in the article, I used Mermaid, a markdown extension that enables embedding UML diagrams in markdown documents. The diagram is described textually and the rendering engine handles the layout.
I knew about draw.io, but never really tried to use it. I considered it in the same category as Microsoft Visio, i.e. generic vector graphic editor with a library of UML symbols. Instead, Draw.io seems quite capable, I'll give it another try.
At my workplace, the tool to use is Quantum Leap QP Modeler. It is a good visual editor that allows you to generate the code. In the past, I have used StarUML which is commercial but allows for an unlimited free evaluation period.
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:


