



Are We Shooting Ourselves in the Foot with Stack Overflow?
Lesson #10 of my Modern Embedded Programming Video Course explains what stack overflow is and shows what can transpire deep inside an embedded microcontroller when the stack pointer register (SP) goes out of bounds. You can watch the YouTube video to see the details, but basically, when the stack overflows, memory beyond the stack bound gets corrupted and your code will eventually fail. If you are lucky, your program will crash quickly. If you are less lucky, however, your program will limp along in some crippled state, not quite dead but not fully functional either. A code like this can kill people.
Stack Overflow Implicated in the Toyota Unintended Acceleration Lawsuit
You probably heard of the Toyota unintended acceleration (UA) cases, where Camry and other Toyota vehicles accelerated unexpectedly and some of them managed to kill people and all of them scared the hell out of their drivers.
The trial testimony delivered at the Oklahoma trial by an embedded guru Michael Barr for the first time in the history of these trials offers a glimpse into the Toyota throttle control software. In his deposition, Michael explains how a stack overflow could corrupt the critical variables of the operating system (OSEK in this case) because they were located in memory adjacent to the top of the stack. The following two slides from Michael’s testimony explain the memory layout around the stack and why stack overflow was likely in the Toyota code (see the complete set of Michael’s slides).
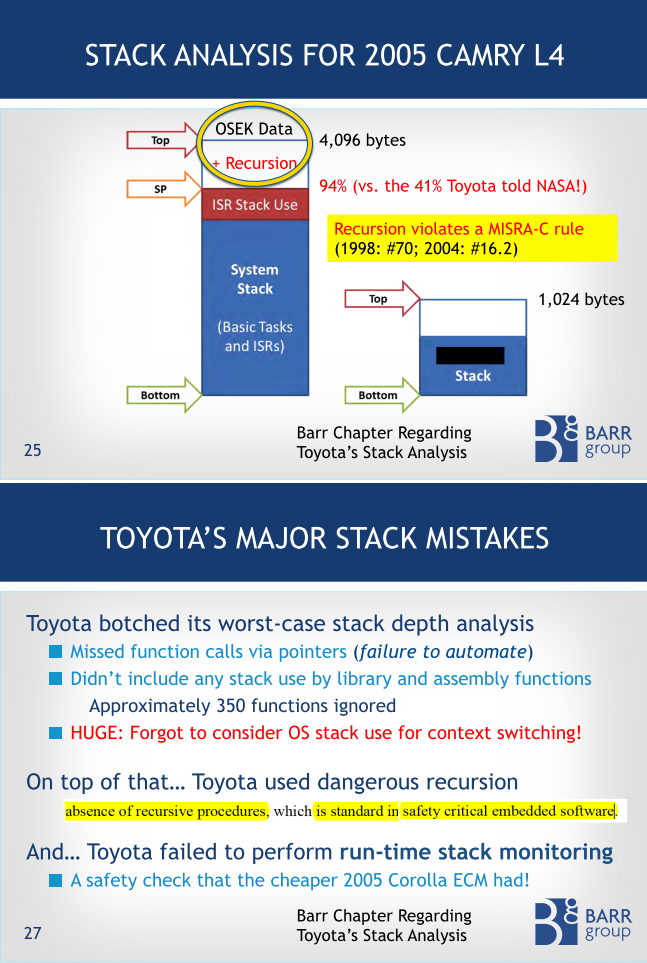
Why Were People Killed?
The crucial aspect in the failure scenario described by Michael is that the stack overflow did not cause an immediate system failure. In fact, an immediate system failure followed by a reset would have saved lives, because Michael explains that even at 60 Mph, a complete CPU reset would have occurred within just 11 feet of the vehicle’s travel.
Instead, the problem was precisely that the system kept running after the stack overflow. However, due to memory corruption, some tasks got “killed” (or “forgotten”) by the OSEK real-time operating system while other tasks were still running. This, in turn, caused the engine to run, but with the throttle “stuck” in the wide-open position, because the “kitchen-sink” TaskX, as Michael calls it, was dead. TaskX controlled the throttle among many other things.
A Shot in the Foot
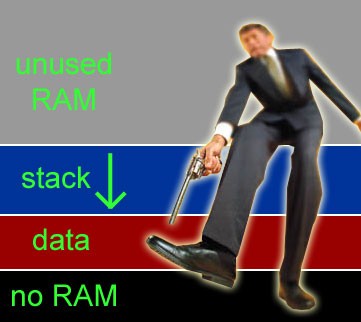
The data corruption caused by the stack overflow is completely self-inflicted. I mean, we know precisely which way the stack grows on any given CPU architecture. For example, on the V850 CPU used in the Toyota engine control module (ECM) the stack grows towards the lower memory addresses, which is traditionally called a “descending stack” or a stack growing “down”. In this sense, the stack is like a loaded gun that points either up or down in the RAM address space. Placing your foot (or your critical data for that matter) exactly at the muzzle of this gun doesn’t sound very smart, does it? In fact, doing so goes squarely against the very first NRA Gun Safety Rule (when they were still interested in safety): “ ALWAYS keep the gun pointed in a safe direction”.
Yet, as illustrated in the Figure above, most traditional, beaten path memory layouts allocate the stack space above the data sections in RAM, even though the stack grows “down” (towards the lower memory addresses) in most embedded processors (see Table below). This arrangement puts your program data in the path of destruction of a stack overflow. In other words, you violate the first NRA Gun Safety Rule and you end up shooting yourself in the foot, as did Toyota.
| Processor Architecture | Stack growth direction |
| ARM Cortex-M | down |
| AVR | down |
| AVR32 | down |
| ColdFire | down |
| HC12 | down |
| MSP430 | down |
| PIC18 | up |
| PIC24/dsPIC | up |
| PIC32 (MIPS) | down |
| PowerPC | down |
| RL78 | down |
| RX100/600 | down |
| SH | down |
| V850 | down |
| x86 | down |
Why Are We Doing This ???
Placing a descending stack above all the data in RAM is the worst possible arrangement we can have. Yet, all default linker scripts in all tools I've ever seen do exactly this. The central question of this post is: Why are we sabotaging almost all of our projects like that?
A Smarter Way
At this point, I hope it makes sense to suggest that you consider pointing the stack in a safe direction. For a CPU with the stack growing “down,” this means that you should place the stack at the bottom of RAM, below all the data sections. As illustrated in the Figure below, that way you will make sure that a stack overflow can’t corrupt anything.

Of course, a simple reordering of sections in RAM does nothing to actually prevent a stack overflow, in the same way as pointing a gun to the ground does not prevent the gun from firing. Stack overflow prevention is an entirely different issue that requires a careful software design and a thorough stack usage analysis to size the stack adequately.
However, the reordering of sections in RAM helps in two ways. First, you play safe by protecting the data from corruption by the stack. Second, on many systems, you also get an instantaneous and free stack overflow detection in the form of a hardware exception triggered in the CPU. For example, on ARM Cortex-M an attempt to read to or write from an address below the beginning of RAM causes the Hard Fault exception. Later in the article, I will show how to design the exception handler to avoid shooting yourself in the foot again. But before I do this, let me first explain how to change the order of sections in RAM.
How to Change the Default Order of Sections in RAM
To change the order of sections in RAM (or ROM), you typically need to edit the linker script file. For example, in a linker script for the GNU toolchain (typically a file with the .ld extension), you just move the .stack section before the .data section. The following listing shows the order of sections in the GNU .ld file.
~~~
SECTIONS {
.isr_vector : {~~~} >ROM
.text : {~~~} >ROM
.preinit_array : {~~~} >ROM
.init_array : {~~~} >ROM
.fini_array : {~~~} >ROM
_etext = .; /* end of code in ROM */
/* start of RAM */
.stack : {
__stack_start__ = .; /* start of the stack section */
. = . + STACK_SIZE;
. = ALIGN(4);
__stack_end__ = .; /* end of the stack section */
} >RAM /* stack at the start of RAM */
.data : AT (_etext) {~~~} >RAM
.bss : {~~~} > RAM
.heap : {~~~} > RAM
~~~
}
Designing an Exception Handler for Stack Overflow
As I mentioned earlier, an overflow of a descending stack placed at the start of RAM causes the Hard Fault exception on an ARM Cortex-M microcontroller. This is exactly what you want because the exception handler provides you the last line of defense to perform damage control. However, you must be very careful how you write the exception handler because your stack pointer (SP) is out of bounds at this point and any attempt to use the stack will fail and cause another Hard Fault exception. I hope you can see how this would lead to an endless cycle that would lock up the machine even before you had a chance to do any damage control. In other words, you must be careful here not to shoot yourself in the foot again.
So, you clearly can’t write the Hard Fault exception handler in standard C, because a standard C function most likely will access the stack. However, it is still possible to use non-standard extensions to C to get the job done. For example, the GNU compiler provides the __attribute__((naked)) extension, which indicates to the compiler that the specified function does not need prologue/epilogue sequences. Specifically, the GNU compiler will not save or restore any registers on the stack for a “naked” function. The following listing shows the definition of the HardFault_Handler() exception handler, whereas the name conforms to the Cortex Microcontroller Software Interface Standard (CMSIS):
extern unsigned __stack_start__; /* defined in the GNU linker script */
extern unsigned __stack_end__; /* defined in the GNU linker script */
~~~
__attribute__((naked)) void HardFault_Handler(void);
void HardFault_Handler(void) {
__asm volatile (
" mov r0,sp\n\t"
" ldr r1,=__stack_start__\n\t"
" cmp r0,r1\n\t"
" bcs stack_ok\n\t"
" ldr r0,=__stack_end__\n\t"
" mov sp,r0\n\t"
" ldr r0,=str_overflow\n\t"
" mov r1,#1\n\t"
" b assert_failed\n\t"
"stack_ok:\n\t"
" ldr r0,=str_hardfault\n\t"
" mov r1,#2\n\t"
" b assert_failed\n\t"
"str_overflow: .asciz \"StackOverflow\"\n\t"
"str_hardfault: .asciz \"HardFault\"\n\t"
);
}
Please note how the __attribute__((naked)) extension is applied to the declaration of the HardFault_Handler() function. The function definition is written entirely in assembly. It starts with moving the SP register into R0 and tests whether it is in bound. A one-sided check against __stack_start__ is sufficient, because you know that the stack grows “down” in this case. If a stack overflow is detected, the SP is restored back to the original end of the stack section __stack_end__. At this point the stack pointer is repaired and you can call a standard C function. Here, I call the function assert_failed(), commonly used to handle failing assertions. assert_failed() can be a standard C function, but it should not return. Its job is to perform application-specific fail-safe shutdown and logging of the error followed typically by a system reset. The code downloads accompanying this article[6] provide an example of assert_failed() implementation in the board support package (BSP).
On a side note, I’d like to warn you against coding any exception handler as an endless loop, which is another beaten-path approach taken in most startup code examples provided by microcontroller vendors. Such code locks up the machine, which might be useful during debugging, but is almost never what you want in the production code. Unfortunately, all too often I see developers shooting themselves in the foot yet again by leaving this dangerous code in the final product.
What About an RTOS?
The technique of placing the stack at the start of RAM is not going to work if you use an RTOS kernel that requires a separate stack for every task. In this case, you simply cannot align all these multiple stacks at a single address in RAM. But even for multiple stacks, I would recommend taking a minute to think about the safest placement of the stacks in RAM as opposed to leaving it completely to the linker to place the stacks somewhere in the .bss section.
Finally, I would like to point out that preemptive multitasking is also possible with a single-stack kernel, for which the simple technique of aligning the stack at the start of RAM works very well. Contrary to many misconceptions, single-stack preemptive kernels are quite popular. For example, the so-called basic tasks of the OSEK-VDX standard all nest on a single stack, and therefore Toyota had to deal with only one stack (see Barr’s slides at the beginning). For more information about single-stack preemptive kernels, please refer to my GitHub repo “Super-Simple Tasker”.
Think!
The most important strategy to deal with rare, but catastrophic faults, such as stack overflow is that you need to carefully think about it! Time-honored, beaten-path approaches might not be the smartest way to go!
Test It!
Once you design your system’s response to various faults, you absolutely need to test it. However, typically you cannot just wait for a rare fault to happen by itself. Instead, you need to use a technique called scientifically "fault injection", which simply means that you need to intentionally cause the fault (you need to fire the gun!). In case of stack overflow, you have several options: you might intentionally reduce the size of the stack section so that it is too small. You can also use the debugger to change the SP register manually. From there, I recommend that you single-step through the code in the debugger and verify that the system behaves as you intended. Chances are that you might be shooting yourself in the foot, just as it happened to Toyota.
I would be interested to hear what you find out. Is your stack placed above the data section? Are your exception handlers coded as endless loops? Please leave a comment!




- Comments
- Write a Comment Select to add a comment
"... warn you against coding any exception handler as an endless loop ... Such code locks up the machine"
What's the alternative to that, for a system in a broken state? A reset might obscure the error. A so severely broken system should show it's broken and refuse to operate normally, once detected?
My handlers so far are a loop that toggles the LEDs of the system in a particular pattern, and pacifies the watchdog on a stm32, which can't be turned off. (my watchdog handler also is directed to there, to prevent reset). The beginning of the handler outputs something on the debug UART, "manually", sans interrupts.
What do you do?

Thanks a lot for the comment because it addresses the critical, but notoriously misunderstood aspect of safe software design.
So, the main purpose of all functional safety standards, (such as IEC-61508 and related) is to design systems that work correctly (are reliable) or fail in a predictable (fail-safe) manner. Specifically, the design must eliminate any "gray area", where the system fails "partially" (such as Toyota vehicles in their unintended acceleration cases). For that reason, the functional safety standards put so much emphasis on failure detection and system self-monitoring.
Now, the "fail-safe" state is a complex concept, which in principle requires performing the FMEA (Failure Modes and Effects Analysis) of the particular system. The subject is too vast to discuss in this comment. You'd need to refer to the functional safety standard documents and tons of other literature.
> My handlers so far are a loop that toggles the LEDs of the system in a particular pattern, and pacifies the watchdog on a stm32
This might or might not be the best "fail-safe" state. It really depends on what your system is doing. However, the fact that you customize your fault handlers is already significant progress from the default endless loops with completely silent denial of service implemented in the standard startup code delivered by the silicon vendors (like ST).
> What do you do?
First, I do everything I can to improve the failure detection in the system. I use the hardware (like the placement of the stack for automatic detection of stack overflow). I use the MPU (e.g., see my blog post NULL pointer protection with ARM Cortex-M MPU). I use the watchdog. But above all, I use a lot of software assertions:
).
As far as the failure handler is concerned, I perform a failure analysis of the system. This might not be a full FMEA every time, but I do carefully think about the best course of action in case of failure. Then I design the failure handler accordingly. I never, ever use the default failure handlers provided by the silicon vendors.
--MMS
100% agree on every point (what a rare thing!). The stack being placed above the globals/statics is something that's bothered me since 1988; unfortunately I haven't had time to fix that in my projects. My general fault handler is not an endless loop as endless loops infuriate me; my fault handlers will attempt to use a logging system to dump information on registers and co-processor registers and this has worked brilliantly except of course in cases where the statics/globals/heap had been corrupted to a degree that the logging facility could not function. Fortunately failure of the logging system is fairly rare - but this is by mere coincidence rather than design and I grind my teeth just thinking about it.
One idea which may be helpful in cases where the stack can crash into the heap or statics/globals is to use the startup code to write a pattern to a chunk of memory at the lower boundary of the stack. On reset most systems will not alter the RAM contents and the startup code can check for damage in the patterned area and the logger can then write some messages post-reset. Corruption of the patterned area can only be taken as an indicator though unless the fault handler can flush the cache prior to reset. If software will occasionally test for damage at the boundary of this patterned area and log information at regular intervals, we may at least get some idea of the risk of a stack crash - although the test scenario will have to be one deliberately crafted to coerce the software towards maximum stack usage.
Thank you for the article, it has given me a renewed interest in looking into putting the heap above the stack.
I'm glad to hear that the suggestions in this post make sense to you.
...it has given me a renewed interest in looking into putting the heap above the stack.
How about avoiding the "Heap Of Problems" altogether?
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:



