



Implementation Complexity, Part II: Catastrophe, Dear Liza, and the M Word
In my last post, I talked about the Tower of Babel as a warning against implementation complexity, and I mentioned a number of issues that can occur at the time of design or construction of a project.

The Tower of Babel, Pieter Bruegel the Elder, c. 1563 (from Wikipedia)
Success and throwing it over the wall
OK, so let's say that the right people get together into a well-functioning team, and build our Tower of Babel, whether it's the Empire State Building, or the electrical grid, or the Internet, or a billion-transistor processor, or an operating system, or a new car, or a jumbo jet, or a space satellite. This team has written a requirements document, and internal interface specifications, and a performs effectively at all levels. And they've overcome the gremlins.
Now what?
Catastrophe: complexity and instability
The development team on the project has gone off and celebrated, and moved on to something else, and has left the Tower in the hands of Qualified People.

Time passes.

Savar building, Bangladesh, 2013
A problem is detected, warnings are ignored, the system fails.

Tradeoffs are made to sacrifice safety to reduce cost, signs of abnormal operation are detected but ignored, unconventional technology is used with higher failure risk, safety tests are skipped, high-energy event exceeds rated operational limits, safety equipment fails, system fails, uncontrolled release of energy and hazardous substances occurs.

Space Shuttle Challenger, 1986
System operated outside design limits, warnings from engineering staff disregarded, system fails.

Engineering solution to reduce cost and promote aesthetics overlooks failure mode, signs of abnormal operation are detected but ignored, system fails.
These are only a few of many large engineering failures. (I would have included Fukushima (2011), and the Therac-25 (1985-87) as additional cases, but could not find any dramatic pictures. The engineering projects of the Citigroup Center and the Old River Control Structure are not catastrophic failures, but are other engineering examples worth studying along the same lines.)
Before we can talk about failures in complex systems, let's talk about failures in a simple system.
Careful with that axe, Eugene...

(Image courtesy of Wikipedia.)
Let's look at an axe with a wooden handle. Assuming the operator uses it properly, what can go wrong? Let's see...
- the handle can break
- the blade can chip
- the axe head can come loose from the handle
That's about it, really. So let's make a state diagram out of it:
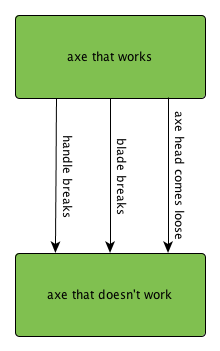
Not too complicated. The upper state is a working axe, the lower state is a nonworking axe, and we transition from one state to another because of these three failure mechanisms.
Now how about a chair:

(Image courtesy of Wikipedia.)
For our purposes of explaining fault analysis, let's make a few artificial assumptions:
- the only things that are likely to break are a leg or one of the spindles connecting the legs
- a chair can still be used with one broken leg (though with reduced stability)
- a chair can still be used with one broken spindle
- more than one broken leg or spindle will cause the chair to collapse and break
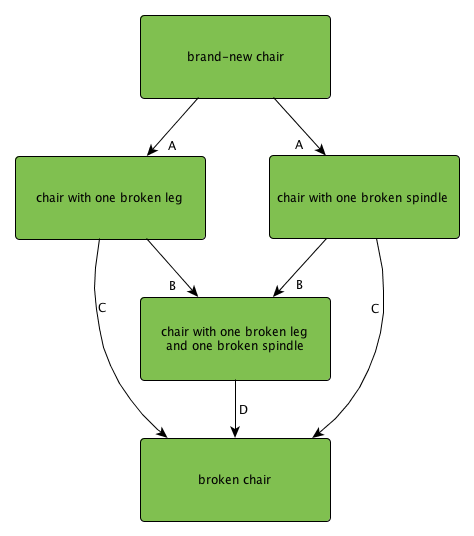
Here we have more states and more transitions. I have arranged the states in order of "health", and labeled the edges with different letters representing different categories. Perhaps the A transitions have a 1% chance of occurring when anyone sits down, the B transitions have a 2% chance of occurring when anyone sits down, the C transitions have a 5% chance of occurring when anyone sits down, and the D transition has a 15% chance of occurring when anyone sits down. The worse shape the chair is in, the more likely it is to suffer complete failure.
We could go on with more examples, but let's stop and go over some principles of reliability engineering and fault tree analysis:
- Redundant components reduce the probability of failure. If both components A and B operate independently and must both fail to cause subsystem X to fail, then the probability that both of them fail is lower than if each of them individually fails.
- Increasing the number of components needed for a subsystem to work, increases the probability of failure. If both components A and B operate independently, and a failure of either one causes subsystem X to fail, then for small failure probabilities, the probabilities add together. (1% per year failure rates of A and B cause an approximate 2% failure rate of X.)
- Components do not operate completely independently: unmodeled dependencies always increase the probability of failure. In general if one component A fails, and its operation is related to component B, then the probability that B fails will be higher as a result of A's failure. This holds true especially for shared loads: if a structural element fails, in general the loads on other parts of the system will be higher and more subject to failure. Another possibility of unmodeled dependencies, is if two components are assumed to operate independently, but they are both prone to the same external failure mechanism (i.e. an earthquake or water ingress or voltage surges or high mechanical loads), then the joint probability of multiple failures is higher.
- In general, systems do not repair themselves; redundancy requires detection and external repair. Let's say subsystem X uses redundant components A and B, which are independent, and each operate with a 10-4 chance per day failure rate. Furthermore, they are both checked once at the end of each day, and immediately repaired if necessary. If one of the components fails, the subsystem still works, and it's repaired before the other can fail. The only way for subsystem X to fail is if both A and B fail in the same day, which has a probability of 10-8 per day. This is the holy grail of redundancy: the failure rates multiply, and turn small chances into infinitesimal chances. But let's say they are checked once every 3 days. If you go through the math, the failure rate is slightly less than 9×10-8 for the 3-day period, or 3×10-8 per day. The more slowly failures in redundant components are detected, the higher the overall chance of failure.
Here is the reliability weakness of very complex systems — there are so many components, that one of the following things is much more likely to happen than for simple systems:
- The probability that there is a single component failing somewhere in the system is much higher
- The probability that there is an undetected single component failure somewhere in the system is much higher
- Reliability of a complex system is highly dependent on the reliability of detecting and fixing single failures
- Unmodeled dependencies in a complex system are much more likely: cascaded failures are more likely than expected, advantages of redundancy are worse than expected
- Design flaws are more likely
Those are technical issues. The management issues are also significant. I picked those four catastrophic failures (Savar, Deepwater Horizon, Challenger, Tacoma Narrows Bridge) because they were the first ones that occurred to me for which I could find pictures, without thinking too much about them... and only later did I have the disturbing realization that all four of them suffered from the same two fatal project management flaws:
- the margin of safety was reduced by cost/time performance pressure (The upper floors of the Savar building were built without a permit and the building was not designed for weight and vibration of heavy machinery; Deepwater Horizon used unconventional cementing techniques, fewer pipe casings than recommended, and had omitted safety devices commonly used in other regions of the world; Challenger was operated at low temperatures which were outside the O-ring design range; the Tacoma Narrows Bridge used thinner girders to improve aesthetics and save money)
- there were signs of early failures that were ignored before the catastrophic failure occurred.
Safety in complex systems really needs to be a non-negotiable requirement.
One additional weakness of many complex systems is the level of energy they contain. Dams, buildings, and bridges all involve structures with a potential energy when they are constructed that is higher than when they fail. As an inherent side effect of their design, there is energy available inside the system itself to magnify the effect of small initial failures. A system which is stable in its normal state can go unstable with small perturbations. This is true as well for fuel storage and transportation: natural gas lines, fertilizer plants, and grain elevators can explode if enough energy is available to ignite the fuel. Nuclear reactors must be protected against the possibility of meltdown, and oil wells must be protected against blowout.
There is a branch of mathematics called "catastrophe theory", which uses the word "catastrophe" in a different sense: it is unrelated to horrible news stories, and unrelated to the applied engineering fields of failure analysis, reliability, or risk management, but rather is a purely mathematical study of dynamic systems, where behaviors can jump from one type to another based on small changes in system state. In engineering, this general concept is something that seems to be inadequately appreciated for risk analysis.
There's a hole in my bucket, dear Liza: dependencies
Let's diverge from failure and risks and catastrophe, and talk about something else found in complex systems.
The children's song, There's a Hole In My Bucket, can be depicted in a graph:
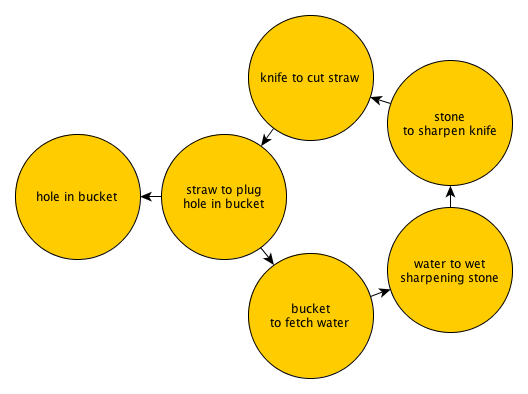
Poor Henry! He has a hole in a bucket, and fixing it depends on using straw to plug the hole, which depends on a knife to cut the straw, which depends on a sharpening stone and some water, but to get the water he needs a bucket, which has a hole in it. A cyclic dependency graph! Too bad for Henry, and of course, perhaps it's his own fault (or Liza's) for creating a system which has cyclic dependencies.
How do we get into cyclic dependencies in the first place? Is it by accident or intentional? Is cyclic dependency a bad thing?
I'm not sure there's a definite answer to those questions. Presumably the processes we put in place in society adapt over time, and become more efficient, and at some point a "bootstrapping" event occurs, where particular goods and services can be produced more profitably if they depend on those same goods and services. To back out of the cycle would be inefficient and unprofitable, so we're stuck in an optimal situation.
This idea is kind of abstract, so to make it a little more tangible, here's a thought experiment:
Pick any independent, healthy adult at random, anywhere in the world. Now bring them to the nearest point outside a building and above solid ground. Then take away everything they own except the clothes they would normally wear while outside. Car keys? Gone. Car? Gone. Wallet, cell phone, passport, house, 401K, job, family? Gone. We'll assume they are not dependent on medical equipment or drugs to survive — otherwise put them back to normal existence and pick someone else.
Now consider some simple tasks, and what it would take to accomplish those tasks.
- Walk around the block. No problem.
- Breathe. No problem.
- Find water to drink. Hmm. Those of us in arid or frozen environments have a problem. Those of us in cities can generally find a public drinking fountain somewhere. In the suburbs? Well, now you've got to ask someone for help or avoid getting reported to the police for acting suspicious. In the forest or countryside? Find a pond or spring or stream, and hope that it's safe to drink, or you've got an immune system up to the task.
- Find food to eat. In cities and suburbs of the developed world, you're going to need money or find a source of charity. If you're in the forest or countryside, it's time to remember which plants are edible.
- Find a safe place to stay. Just make sure you're not trespassing on someone's territory, or violating any local laws. Watch out for dangerous animals or malicious people. Pick a spot where you have shelter from the sun and wind and rain. Sleep tight....
- Write a computer program which displays the first N primes, given N as an integer. Huh? How did we get from water, food, and shelter to computer programming? Well, in any case, the programming is the easy part; the hard part is finding a computer. If you're close to a library, then you're probably in luck.
- Find a job. Hmm. Well, you're going to need to locate an open position that fits your skills. And you'll need a resume, which you can print out at the library, I guess. In your resume you'll need to put past experience along with your college credentials... oh, did we mention those got taken away as well? OK, that narrows your options. Now you probably need to put down your address and phone numbers. And to get hired in the United States you'll need to list your Social Security Number, and show proof you're a US citizen or permanent resident. That won't be a problem, will it? On top of all that, you should wear a nice shirt and make sure you make a good impression.
Anyway, you get the picture. We depend on things. Furthermore, we depend on things with cyclic dependencies. To get a job you generally need enough money to show some basic measure of stability including a place of residence; and to get that money you need a job or another source of income; to rent a place to live, or apply for a mortgage on a house, you generally need to list a source of income as well.
Now let's get back to more complex systems. But we'll start simple. Consider Apple's iPhone. Or maybe it's not so simple. Cassidy and her friend Kaitlin both have iPhones. Cassidy calls Kaitlin and they talk for two hours. What does it take to make that happen?
Okay, assuming we have iPhones, we need a telecommunications infrastructure. No cell phone towers, no telephone call.
Then we need to revisit how iPhones get distributed. There's a global sales network of Apple stores and other distributors carrying iPhones all throughout the world, with container ships and trucks and the like bringing them forth. Oh, that means we need gasoline to transport them. Which means we need oil refineries and pipelines and wells and seismic exploration equipment....
Before they can be distributed though, they need to be manufactured. So we have factories in China, assembling circuit boards with components made out of all sorts of materials. Glass for the display needs a high-temperature furnace among other things. Integrated circuits need all sorts of nasty chemicals. Capacitors for high-density energy storage are frequently made out of tantalum; the huge demand for tantalum has caused all sorts of problems for Central Africa, where it is mined. (But apparently the attention is bringing some positive changes.)
And before manufacturing is design. The efforts to make a high-volume consumer product like the iPhone are amazing. I've worked on electronics designs myself, and I can't imagine how many man-years it has taken just to bring the design of the iPhone to fruition. I would guess tens of thousands. And each of those contributors to the design of the iPhone has to be fed, and clothed, and housed....
Is an iPhone hard to use? No. Interface complexity: very good. Implementation complexity? Pretty darn high.
But that's okay, because Apple has gone into the business of making iPhones knowing full well the impact of all these logistical issues, right? Any large company that designs and makes things has to have a good knowledge of supply chain management.
Here's some food for thought:
- Over 55% of the total semiconductor foundry revenue comes from companies based in Taiwan. Taiwan faces risk from both earthquakes and the tension between it and China over Taiwan's independence.
- In 2011, there were severe floods in Thailand that caused a global shortage of hard disk drives; at the time, Thailand made 25% of the world's hard disk drives, and prices doubled after the flooding.
- China dominates the production of rare earth materials used for permanent magnets; in 2010 China restricted exports of rare earth materials, causing a skyrocketing price of rare earths (with ripple effects to permanent magnets and motors) which has since subsided to more normal price levels.
Are these dependencies exposing us to undue risk? Maybe yes, maybe no. Again, large companies have to plan for the possibility of supply chain disruption, and usually take steps to diversify. As consumers, we get hit with price increases — but these problems don't cause catastrophic changes in our lives. The worst consequences we run into are minor inconveniences: an airplane flight gets canceled, or a TV show is pre-empted, or there's more traffic than usual, or there's a shortage of Eggo waffles or Twinkies. That's about the worst that can happen.
Or is it?
What about drug shortages? In recent years there have been increasing numbers of drug shortages. Notable examples include Tamiflu, a flu vaccine dependent on the ability to process star anise, an evergreen tree found in southern China and northern Vietnam; Heparin, a blood thinner manufactured chiefly from pig and cow tissue; Kanamycin, an antibiotic used to treat drug-resistant tuberculosis; Leucovorin, a type of folic acid used to treat colon cancer; and Propofol, an anesthetic.
Our transportation and utility infrastructure is woefully vulnerable to failures, whether they occur in bridges, roads, water reservoirs, aqueducts, or electric transmission lines. Next time you travel to work, look at your other options should there be a blocked transportation artery. This can happen to major cities, like San Francisco or New York, or in rural areas, where there are natural barriers like mountains or rivers with few crossings. A 23-mile stretch of US Highway 89 in the northwest part of Arizona, between Bitter Springs and Page, has now been closed for four months as of June 2013, due to a landslide; the two nearest detours on paved roads are each around 160 miles. This is an extreme case; in many cases there are redundancies to prevent a single failure from stopping the system — there are two highways connecting the Florida Keys to the rest of the state; Boston's connection to the Wachusett Reservoir is through two separate aqueducts, and a closure of the I-95 Bridge between Cambridge, Massachusetts and Boston would not cut off Boston completely from its neighbors — but our transportation networks are regularly overloaded, and any temporary capacity reduction can cause significant delays.
Even if there are redundancies and disaster management plans on the scale of large communities, our individual dependence on a reliable infrastructure can get us into trouble. How many of you have let a drug prescription get down to a few days' remaining supply before getting a refill? I've done this once or twice, and what starts as mere procrastination can become panic when I can't make it to the pharmacy before it closes, and the next day is Easter, or I have to go on a business trip. The cost of making foolproof, reliable plans is too high when no storm clouds are in sight, and by the time a potential disaster is about to strike, it's too late, and we're stuck with whatever plans we've made. Large companies have people to deal with risk management, but as individuals all we have is ourselves.
This Battery Cannot Be Used: assumptions and the curse of proprietary dependencies

I bought a Panasonic digital camera in September 2010, and because I like redundancies, as usual I bought a backup battery. The battery was from Lenmar, a reputable aftermarket battery manufacturer, and was supposed to be compatible with my camera. When I went to use it, my camera worked normally for about 10 seconds, but then displayed the message THIS BATTERY CANNOT BE USED, locked up for a little while, and then shut off. I had to return the battery and purchase a more expensive one from Panasonic. The technology exists now to embed a small integrated circuit inside the battery with a cryptographic authentication protocol to ensure it is not a "counterfeit" battery.
I get it, Panasonic: you are a business trying to safeguard both your income and your brand's reputation. Indeed, there are counterfeit batteries out there, and with the advent of lithium batteries, it's not just a business issue but also a safety issue. Part of the cost of high-quality lithium batteries comes from the requirement to contain active protection circuitry, which disconnects the battery in the event of a short circuit, since defects or overstresses in lithium batteries can cause them to catch fire or explode. Counterfeit batteries may circumvent these safety mechanisms. And as a result, modern cameras have anti-counterfeiting features used to detect batteries not authorized by the manufacturer.
So here's the rub: not only did my camera detect an unauthorized battery, and report this fact to me, but it denied me the opportunity to use that battery. Panasonic took away the right for me to choose which battery to use. What happens when my camera battery reaches the end of its life, and I find out Panasonic no longer makes it, but I still like my camera? As a result of Panasonic making the assumption that the company is solely qualified to decide which batteries are acceptable, it has created an artificial dependency on its own proprietary batteries.
Batteries are not the only example of this kind of dependency; ink cartridges and toner cartridges have similar anti-counterfeit measures. Apple's new "Lightning" connector for the iPhone 5 is a proprietary connector with authentication features; Apple tightly controls the distribution of these connectors and ships them only to authorized 3rd-party manufacturers participating in its MFi licensing program.
This year I finally upgraded my cell phone to a smart phone; I bought an Android phone from Samsung, with a Micro-USB charging port, a replaceable battery, and a micro-SD card slot, all so I could remain free of proprietary dependencies.
And it's not just consumer goods that have a trend of increases in authenticated proprietary accessories. Medical device manufacturers are introducing authentication into disposable components of their products. These are items like syringes, dialysis bags and cassettes. The idea is that only the original manufacturer can be trusted to provide quality-controlled sterile supplies for their equipment; in some cases single-use medical items are being reprocessed and resterilized in order to save money, but this can also cause serious risk for contamination. Again, I get it; company X wants to make sure that its quality controls, which are expensive and painstakingly put into place, are not bypassed to bring damage to patients and to its reputation. But what happens in an emergency situation? Suppose that a hospital in a disaster area has a spike in the number of patients for a certain treatment. The hospital runs out of Authenticated Flodget Bags, and has an autoclave they can use to sterilize them, but they are useless, because the Flodget Machine has proprietary authenticated accessories, and won't allow the machine to run with Flodget Bags that have been previously used. In an emergency, it should be an informed decision made by the doctor and patient, not by the Flodget Company.
All in all, proprietary dependencies limit the usefulness of a product to the life cycle of its supplies, rather than the durability of the product itself. If the proprietary supplies are interrupted or discontinued, the product is useless.
Maintenance: the M word
There's one more aspect of implementation complexity that I want to talk about, and that's maintenance.
Remember this diagram, from when we talked about failure mechanisms in a chair?
The arrows are all one-way state transitions, leading from perfect to broken. With rare exceptions, the objects and systems we manufacture are not self-repairing. If you get a light scratch or cut, your body will generally heal, but if your cell phone gets a light scratch or cut, it will remain that way. In order for a complex system to keep working, when a part breaks, it has to be replaced. In addition to vigilant failure detection and repair, many systems need preventive maintenance. Roads need regular cleaning and repaving. Steel bridges in maritime areas need regular repainting, due to exposure from salt spray or salt fog. Your car needs its oil and tires changed, along with filters, spark plugs, shock absorbers, brake pads, and so on and so forth.
Even software requires maintenance — and not just if a bug is discovered. Databases need to ensure they are regularly checked for integrity (in the rare but possible case of data errors). Now that many software programs utilize communication links over the Internet, there are assumptions that can change over time, and software that is bug-free when it is released can have bugs that show up later when the world around it changes.
Designers of complex systems are usually aware of maintenance issues, and will plan ahead. But that's often because technology is mature, and engineers have had time to learn what's needed. New technology has the potential for unforeseen problems, and it will take time to learn all the maintenance required to make today's leading-edge technology reliable.
Quite honestly, I would reject attempts at a modern Tower of Babel, merely because of the maintenance costs.
So if you're lucky enough to be part of a design team, remember that the dangers of complexity don't just stop when the design is complete.
What now?
Okay, so you've been patient enough to read this whole post. So what? The world is complex, we aren't going to just give it up, are we? And what does this have to do with embedded systems, anyway?
In a nutshell, here's what I've discussed:
- Design complexity often makes projects late and costly, and more prone to failure before they are even completed. Gremlins are afoot everywhere!
- Managing design complexity in large projects requires efforts of a completely different magnitude from small projects. This is due, in large part, to communication and cognitive limitations of people — to wit, the Tower of Babel's revenge.
- Operational complexity (after design and construction is complete) can cause unintended and dangerous consequences, reduce reliability, commit a project to high long-term operating costs, or limit its useful lifetime.
How can we learn to manage complexity, then?
- Be aware of complexity. We all need to be more aware of it, not only as product and system designers, but as administrators and consumers. The benefits of complex technological innovations are widespread, valuable, and apparent. The risks are often hidden. We need to treat complex systems as though they are icebergs, and be cognizant of the entire consequences of complexity, not just the immediate benefits.
- Avoid unnecessary complexity. Again, there are benefits and there are consequences. If the benefits go to waste, complexity is a liability.
General advice for design engineers:
- Learn more about the consequences of your design decisions, not just how they affect you, but how they affect your colleagues and customers.
- More specifically, make sure you know the consequences of errors in your design. If you're working on musical greeting cards or audio players, not much can go wrong. If you're working on home thermostats, or garage door openers, or automobile power windows, or anything where a design flaw can cause injury or property damage, you really should make sure you understand some basic concepts of risk management and reliable systems engineering.
- Learn from other disciplines. The Mythical Man-Month is aimed at software engineers, but is a good resource in general. At one point in the book, the author cites a rule of thumb to successful project scheduling as 1/3 planning, 1/6 coding, 1/4 component test, 1/4 system integration. That means if you just spent an intense couple of months constructing the details of a design, congratulations, but 83% of the design effort lies elsewhere.
- Beware the short-term fix. It's so appealing. You want to add some little dinglewhosy to a design to handle a corner case, and it solves your short-term problems, but you're blocking out the fact that you'll have to test it, and understand how it affects your system reliability. And it's going to add even more corner cases when interacting with existing parts of the design. If you understand these issues, but are being pressured by management to ignore them for the sake of expediency, that's a red flag.
Advice for circuit designers:
You have it easy; the complexity of your design is, for the most part, proportional to circuit board space. Once the space constraints are fixed, it's hard to go too overboard. Still, there are a few ways to keep the gremlins at bay:
- Long before you finish a detailed design, work very hard to get a consensus on the requirements and signal interfaces of your circuit board, and write those requirements down. When a design is 90% done, it's late in the game to add features for ESD protection and electromagnetic compatibility as an afterthought, or expand the ambient temperature range.
- Flexibility = complexity. Beware of general-purpose circuit boards. Yes, for a proof of concept you can mitigate risk by leaving open options in the form of test points, headers, connectors, prototyping areas, bus switches, spare op-amps, etc. but don't overdo it. The techniques that work well in software for modularity don't translate easily to hardware, and signal integrity can suffer. There's a reason you don't see chip sockets on circuit boards much anymore.
- While you're working on a circuit design, and definitely when it's approaching completion, keep refining a written design description. You've spent a lot of effort making specific choices on what component values to use — don't throw that effort away by not writing it down. If you have to change your design later, because of specification changes, you will need that design description yourself. And you'll save a huge amount of time and effort explaining your design to various coworkers, if you can just hand them a written description.
Advice for software engineers:
Complexity is the road to hell, paved with good intentions. Oh, it's so easy to add more features — never mind the customer, you want them for yourself to make future reuse easier, so you can kill 10 birds with one big complex stone, rather than with 5 little stones.

- Beware of Swiss-army-style software components. You know what I'm talking about. It's those classes with 25 different methods, some of which handle these little weird specific cases. Components with high feature count are usually a sign that something is wrong. Split them into simpler pieces.
- Be careful using metaphors for naming things in software. The advantage of a good metaphor is that it takes some complex software concept, and tells the reader, "Hey, you know that XYZ you deal with in the real world? This software is really the same thing; you don't have to work to understand how it operates, just use a mental model of an XYZ." The disadvantage of a sloppy metaphor is that the thing in the real world is slightly different than the thing in software, and you now have to somehow disambiguate the two, which is probably harder than if you just kept them as separate concepts. Two that come to mind are the infamous
IMonikerfrom Microsoft COM (ah, it's nice to be free of that stuff), which is kind of like a name for COM objects, but not quite.... and in Python, the variants ofConfigParser: we haveRawConfigParser, andConfigParser, andSafeConfigParser, which differ in the way that they treat the so-called "magical interpolation feature". (Note to self: avoid using "magic" or "magical" in software descriptions)RawConfigParserdoesn't do any interpolation,ConfigParserdoes, but there's nothing in the name to indicate this, andSafeConfigParserdoes interpolation as well but it is a "more-sane variant". (Another note to self: avoid using "sane" or "more-sane", especially when distinguishing between two software features, both of which you have produced. PerhapsConfigParsershould be renamed toManicConfigParserto complete the analogy?) The term "raw" is used well here, but the other two class names aren't useful. What probably would have been better is to just have oneConfigParserwith a pluggable interpolation handler. In any case, the point is that metaphors come with their own baggage, and if misapplied to complex subjects, they can cause more harm than good. -
State machines are golden opportunities for errors. They're like a bowl of food with a little sign saying Gremlins Welcome! You had better be very careful, both when designing state machines, and when implementing them. If you're using an ad-hoc approach with a
statevariable andswitch/casestatements that handle each value ofstateand modifystatein each case, you're opening yourself up to trouble. Here's the deal: in order for state machines to work correctly, there are a few subtleties. You've got to make sure that initialization of state variables happens correctly — whether it's the beginning of the program or an explicit reinitialization later — and you've thought through all the state transitions correctly. The problem with the ad-hocstatevariable approach, is that you're likely to do something like this:switch (state)
{
...
case STATE_FOO:
if (input == YOYODYNE)
{
output = ZIPPY;
++othersideeffect;
state = STATE_BAR;
}
break;
case STATE_BAR:
...
} // end of switch statement
// global condition:
if ((othersideeffect < 2) && (ambientTemperature > 66))
{
state = STATE_BAZ;
}
This code shows a
STATE_FOO→STATE_BARtransition, and also a global condition that puts the state machine intoSTATE_BAZ. So the question here is, did you really intend for the global condition to act upon the state variables as they are after the switch statement has already taken effect, with possible state changes? Or is the global condition supposed to be executed instead of the switch statement — in which case this code has a bug and the global condition should be in an if/else statement further up? Don't ask me, I don't know what your hand-coded state machine is supposed to do. - Use immutable variables as much as possible. I can't do this topic justice; there's been a lot written about functional programming and avoiding mutable state and side effects. It reduces complexity of code, if you know portions of code produce outputs which are pure functions of their inputs. Check out the coverage of this topic in point #15 in Josh Bloch's Effective Java.
- Don't be clever. So you've just figured out how to make a state bit serve double duty for two different functions: you've had a flash of insight and it reduces both the code and data space requirements, you just need to write a quick 20-line comment in the code explaining to everyone how this works, and how the bitwise AND operator and the minus sign treat each of the 3 possibilities correctly in your design. Great! Now select this text, and use the cut-and-paste feature of your editor to remove it from the code, and file it away into a directory you call
/etc/CleverThingsThatAreBestAvoided. Really. It's not worth it. I guarantee that piece of code will cost you hours of unnecessary hassle if it ever shows up in a completed library or product.
That's it for today! Remember: keep it simple!




- Comments
- Write a Comment Select to add a comment
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:



